Total: $0.00
Taxes and shipping calculated at checkout


MegaMatcher Standard Accelerator 3.0 is a solution for fast template matching on server-side part of a large-scale AFIS or multi-biometric system. The Extended versions of this product include server hardware and software for fast biometric template matching on server-side part of a large-scale AFIS or multi-modal system. The Standard version is intended to be run on a common PC/Server and does not include any hardware.
MegaMatcher Accelerator 3.0 Extended units and MegaMatcher Accelerator 3.0 Standard software can be purchased by new and existing MegaMatcher SDK, VeriFinger SDK and VeriEye SDK customers.
Different large-scale biometric projects may require specific system performance. These matching engines and architectures may be used depending on the required matching speed, database size and system availability:
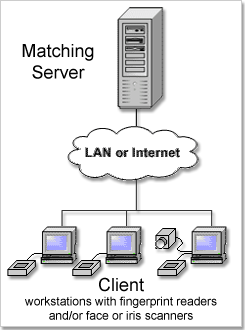 Matches 160,000 fingerprints or 1,200,000 faces or 1,440,000 irises per second. Requires MegaMatcher 4.0 Standard SDK.
|
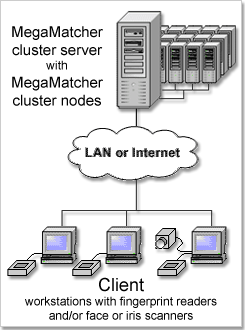 Matches up to several millions fingerprints or faces or irises per second. Requires MegaMatcher 4.0 Extended SDK.
|
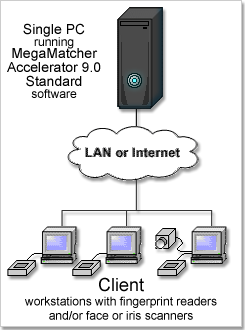 Matches 35,000,000 fingerprints or 70,000,000 irises per second. Requires MegaMatcher 4.0 SDK, VeriFinger 6.3 SDK or VeriEye 2.3 SDK for client application development and 1 MegaMatcher Accelerator 3.0 Standard software installation.
|
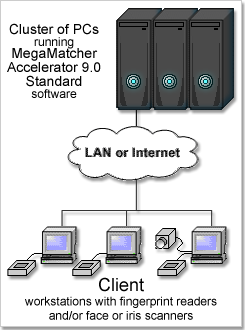 Matches from 70,000,000 to 350,000,000 fingerprints or from 140,000,000 to 700,000,000 irises per second. Requires MegaMatcher 4.0 SDK, VeriFinger 6.3 SDK or VeriEye 2.3 SDK for client application development and multiple MegaMatcher Accelerator 3.0 Standard software installations for reaching the required performance.
|
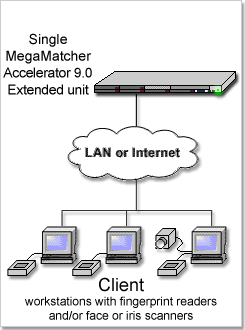 Matches 100,000,000 fingerprints or 200,000,000 irises per second. Requires MegaMatcher 4.0 SDK, VeriFinger 6.3 SDK or VeriEye 2.3 SDK for client application development and 1 MegaMatcher Accelerator 3.0 Extended unit.
|
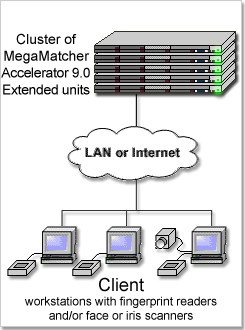 Matches from 200,000,000 to several billions fingerprints or from 400,000,000 to several billions irises per second. Requires MegaMatcher 4.0 SDK, VeriFinger 6.3 SDK or VeriEye 2.3 SDK for client application development and multiple MegaMatcher Accelerator 3.0 Extended units for reaching the required performance.
|
It is possible to use more than one architecture within a large-scale biometric system to reach optimal system performance and/or availability. For example, MegaMatcher Accelerator 3.0 unit(s) can be used for candidates selection using irises or several fingerprints, and then the results can be validated on Matching Server or Cluster with other biometric modalities. Also, two or more Clusters Servers or MegaMatcher Accelerator 3.0 clusters can be connected together for high availability system.
The architecture with a single Matching Server is intended to be used in moderate size systems like local AFIS or multi-biometric system which do not have strict requirements on performance or availability. The Matching Server software is available in MegaMatcher 4.0 Standard and Extended SDKs, as well as in VeriFinger 6.3 Extended SDK, VeriLook 5.0 Extended SDK and VeriEye 2.3 Extended SDK.
A PC running Matching Server software accepts identification requests from client-side components for fingerprint, face and/or iris biometrics and returns back the identification results. Up to 160,000 fingerprints or 1,200,000 faces or 1,440,000 irises per second can be matched on single Matching Server (on Intel Core2 processor with 4 cores running at 2.66 GHz).
The Matching Server can be also used for multi-biometric systems that use any combination of these biometric modalities: fingerprints, faces and/or irises.
This architecture is designed for high productivity AFIS or multi-biometric system with millions of biometric templates stored in the database. The Cluster Server component is available in MegaMatcher Extended SDK.
Cluster Server distributes identification task over computers connected to the network. A biometric system based on Cluster Server software can be scaled up anytime to meet changing project requirements in increasing user amount or request environment. The cluster software consists of a Cluster Server and software for cluster nodes that run fingerprint, face and/or iris components.
The Cluster Server accepts requests from client side, manages cluster work, distributes tasks over cluster nodes, collects results, reports them back to client side. Also it communicates with the main database which stores the biometric data.
Each cluster node matches up to 160,000 fingerprints or 1,200,000 faces or 1,440,000 irises per second (on Intel Core2 processor with 4 cores running at 2.66 GHz). The Cluster Server can be also used for multi-biometric systems that use any combination of these biometric modalities: fingerprints, faces and/or irises.
A cluster node contains part of the main database, performs identification tasks in it and reports results to the Cluster Server. The node must have enough memory to store that database part, as all data is kept in memory during identification to achieve the best matching speed. A larger number of nodes results in faster matching, because each node operates on a smaller part of the database.
The cluster node uses database to store its database part and in order to perform relational queries, such as filter persons by gender, age, living place.
The amount of required cluster nodes is calculated is this way:
Two methods of node fault tolerance are implemented in Cluster Server software:
We recommend to leave at least 10%-20% free memory reserve when calculating the amount of used nodes in a cluster for both fault tolerance methods. The memory reserve would allow to avoid situations when the system can not continue work as it has not enough resourses.
MegaMatcher Accelerator 3.0 is a solution for large-scale AFIS and multi-biometric projects and is available in two versions:
A MegaMatcher Accelerator 3.0 unit accepts identification requests from PCs that run client-side software based on components for fingerprint, iris or face biometrics, performs identification and returns back the results.
MegaMatcher Accelerator can be also used as a part of scalable multi-biometric identification system that uses fingerprint, face and/or iris modalities. The fingerprints and/or irises would be matched using MegaMatcher Accelerator(s), whereas other modalities would be matched using Matching Server or Cluster Server software depending on project size and performance requirements. Also MegaMatcher Accelerator 3.0 software includes fingerprint, face and iris matching engines that may be used for results validation after fast fingerprint or iris matching inside the Accelerator unit instead of using MegaMatcher Server or Cluster.
MegaMatcher Accelerator 3.0 Standard and Extended versions already include cluster software, thus multiple MegaMatcher Accelerator 3.0 Standard or Extended units can be connected via network to a cluster.
To create a cluster, one MegaMatcher Accelerator unit is assigned as a primary unit in the cluster while other MegaMatcher Accelerator units act as cluster nodes. Note that the primary unit of MegaMatcher Accelerator cluster will still perform fast fingerprint and/or iris matching while using only a small part of its resources for managing the cluster.
Each MegaMatcher Accelerator 3.0 Standard unit in the cluster matches 35 millions fingerprints or 70 millions irises per second, and each MegaMatcher Accelerator 3.0 Extended unit matches 100 millions fingerprints or 200 millions irises per second.
When started, the primary unit splits the whole biometric database, which is stored on its hard disk, and send parts of the database to all MegaMatcher Accelerators in the cluster. Later the primary unit waits for fingerprint and/or iris identification requests from client side, then distributes the identification request to the units of the cluster and returns the identification results to the client side.
The cluster of MegaMatcher Accelerators can be scaled up anytime to meet changing project requirements in increasing user amount or request environment. A larger number of MegaMatcher Accelerator units results in faster matching and higher number of requests processed, because each unit operates on a smaller part of the database.
For example, there is a database with 10 million people biometric data (4 fingerprints for each user, 40 million fingerprints in total). The amount of required MegaMatcher Accelerator units is calculated is this way:
Fault tolerance for a cluster of MegaMatcher Accelerators can be provided using these methods:
Note, that "spare cluster" and "two parallel clusters" methods may require additional software and hardware for building high-availability clusters.
MegaMatcher Accelerator 3.0 Standard is a family of ready-to-use software products for fast fingerprint and iris matching on server-side part of an AFIS or multi-biometric system. These products are intended for large-scale biometric projects with up to several million people enrolled in database.
Client communication module that allows sending a task to the MegaMatcher Accelerator, querying status of the task, getting the results and removing the task from it, is included with MegaMatcher 4.0 SDK, VeriFinger 6.3 SDK, VeriLook 5.0 SDK and VeriEye 2.3 SDK. This module hides all low level communications and provides high-level API for the developer.
Database storage capacities for single MegaMatcher Accelerator 3.0 unit are:
If a biometric template contains several fingerprint and/or iris records, the database storage capacity changes proprtionally. The table below shows storage capacities for some combinations of fingerprints and/or irises records; there are no limitations on the quantity of fingerprint or iris records in a template. Please Contact Us to help you determine how many MegaMatcher Accelerators would be required for a specific project.
| Database storage capacities for single MegaMatcher Accelerator 3.0 unit | ||
|---|---|---|
| One template contains: | MegaMatcher Accelerator 3.0 Extended |
MegaMatcher Accelerator 3.0 Standard |
| 1 fingerprint record | 30,000,000 templates | 3,000,000 templates |
| 2 fingerprint records | 15,000,000 templates | 1,500,000 templates |
| 1 iris record | 50,000,000 templates | 5,000,000 templates |
| 2 iris records | 25,000,000 templates | 2,500,000 templates |
| 1 fingerprint + 1 iris records | 18,750,000 templates | 1,875,000 templates |
| 1 fingerprint + 2 iris records | 13,635,000 templates | 1,363,500 templates |
| 2 fingerprint + 1 iris records | 11,535,000 templates | 1,153,500 templates |
| 2 fingerprints + 2 iris records | 9,375,000 templates | 937,500 templates |
| 4 fingerprint + 1 iris records | 6,520,000 templates | 652,000 templates |
| 4 fingerprints + 2 iris records | 5,765,000 templates | 576,500 templates |
The tables below show the performance of MegaMatcher Accelerator 3.0 fast fingerprint and iris matching engines performance on the specified hardware.
| Fingerprint matching speed (templates per second) | ||
|---|---|---|
| One template contains: | MegaMatcher Accelerator 3.0 Extended |
MegaMatcher Accelerator 3.0 Standard |
| 1 fingerprint record | 100,000,000 | 35,000,000 |
| 2 fingerprint records | 72,000,000 | 21,000,000 |
| 4 fingerprint records | 29,000,000 | 8,500,000 |
| 10 fingerprint records | 11,500,000 | 4,000,000 |
| Iris matching speed (templates per second) | ||
|---|---|---|
| One template contains: | MegaMatcher Accelerator 3.0 Extended |
MegaMatcher Accelerator 3.0 Standard |
| 1 iris record | 200,000,000 | 70,000,000 |
| 2 iris records | 100,000,000 | 35,000,000 |
MegaMatcher Accelerator 3.0 Standard was tested on hardware with these specifications:
|
These template databases were used for testing MegaMatcher Accelerator 3.0 template matching algorithm reliability:
|
Database 1 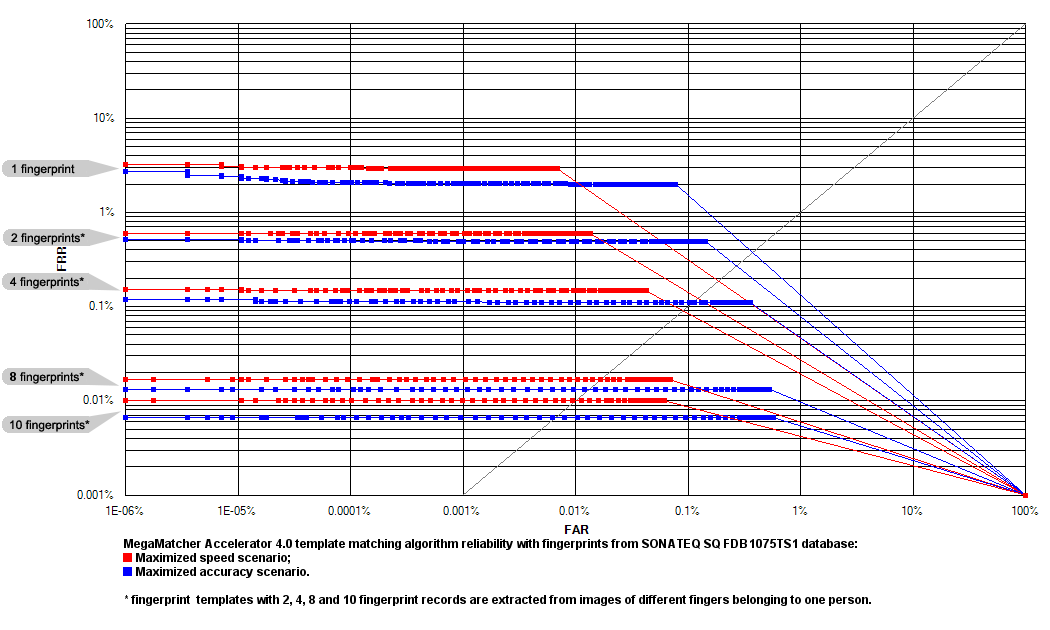 Click to zoom Database 2 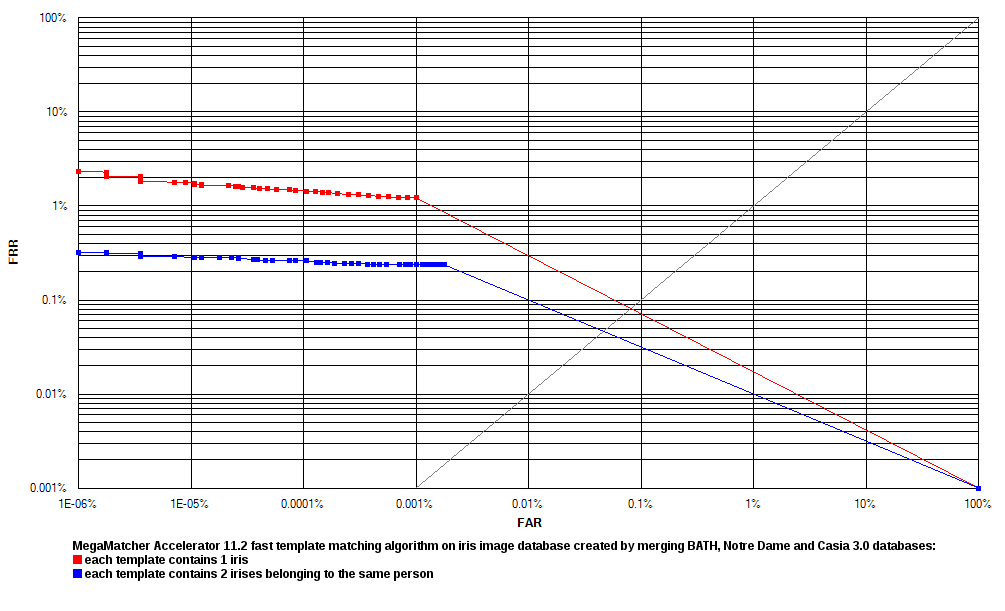 Click to zoom Database 3 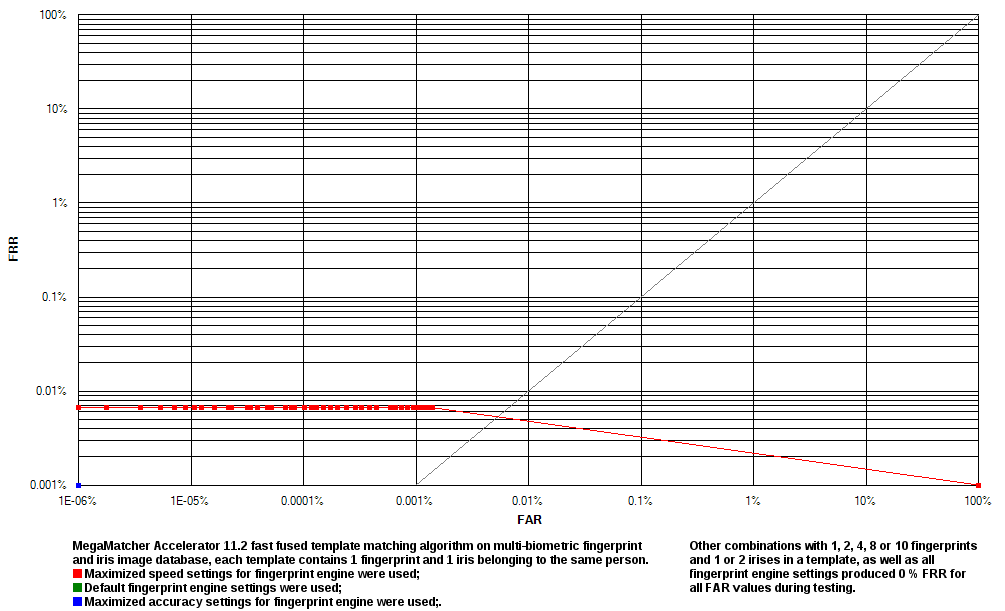 Click to zoom |
Reliability testing results for the MegaMatcher Accelerator 3.0 fingerprint template matching algorithm are shown as a receiver operation characteristics ( ROC) charts. Note, that all tests with Database 3, except 1 finger + 1 iris, produced 0% FRR for all FAR values.
The MegaMatcher Accelerator 3.0 template matching algorithm performance was tested with full database capacities for both Standard and Extended units as specified above. The table below shows the performance testing results:
| MegaMatcher Accelerator 3.0 matching speed testing (million templates per second) | ||
|---|---|---|
| One template contains: | MegaMatcher Accelerator 3.0 Extended |
MegaMatcher Accelerator 3.0 Standard |
| 1 fingerprint record | 124.76 | 37.28 |
| 2 fingerprint records | 89.46 | 22.18 |
| 4 fingerprint records | 35.57 | 8.76 |
| 10 fingerprint records | 13.97 | 3.91 |
| 1 iris record | 219.79 | 73.66 |
| 2 iris records | 108.70 | 36.10 |
| 1 fingerprint + 1 iris records | 79.55 | 26.23 |
| 1 fingerprint + 2 iris records | 55.64 | 18.46 |
| 2 fingerprint + 1 iris records | 62.20 | 18.55 |
| 2 fingerprint + 2 iris records | 47.84 | 13.23 |
| 4 fingerprint + 1 iris records | 30.52 | 8.63 |
| 4 fingerprint + 2 iris records | 26.19 | 7.16 |
| 10 fingerprint + 1 iris records | 12.99 | 4.32 |
| 10 fingerprint + 2 iris records | 12.19 | 3.97 |











